蘋果公司最新發布的A19系列處理器中,旗艦型號A19 Pro憑借性能突破引發行業關注。這款采用臺積電3nm(N3P)制程工藝的芯片,在CPU與GPU性能上均實現顯著提升,尤其在單線程處理能力方面展現出超越桌面級處理器的實力。

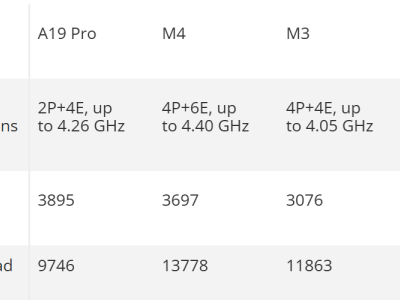
在CPU架構設計上,A19 Pro延續6核配置,包含2個高頻性能核心與4個能效核心。性能核心主頻提升至4.26GHz,較前代增長6.5%,同時通過改進分支預測算法和增加前端帶寬,顯著提升指令處理效率。能效核心則通過擴大最后一級緩存(增加50%)優化多任務處理能力。實測數據顯示,該芯片在Geekbench 6單線程測試中取得3895分,不僅超越自家M4桌面處理器5.3%,更領先AMD銳龍9 9950X達11.8%。不過受限于6核架構,其多線程得分9746分僅較前代提升12%,與臺式機處理器仍存在差距。
制程工藝的升級為性能提升奠定基礎。N3P工藝作為N3E的光學縮小版,在相同功耗下可提升4%晶體管密度與5%性能,或在相同頻率下降低5%-10%功耗。這種技術突破使得A19 Pro在維持iPhone 19 Pro鋁合金機身與均熱板散熱設計的前提下,仍實現主頻與能效的雙重優化。值得注意的是,蘋果未通過極端拉高頻率獲取峰值性能,而是側重分支密集型工作負載與IPC(每時鐘周期指令數)的提升,盡管這種策略在基準測試中尚未完全體現優勢。
GPU領域成為本次升級的最大亮點。A19 Pro提供5核與6核兩種GPU版本,均搭載第二代動態緩存技術與統一圖像壓縮功能。其中5核版本集成神經加速器,峰值算力達前代3倍,宣稱可實現MacBook Pro級圖形性能。6核版本在Geekbench 6測試中取得45657分,較前代提升37%,性能水平與iPad Air的M2/M3 GPU及AMD Radeon 890M集成顯卡相當。

AI計算能力的強化是另一重要突破。A19 Pro首次引入矩陣乘法加速單元,彌補了此前缺乏專用張量計算核心的短板。該單元可顯著提升神經網絡運算效率,尤其在矩陣乘法這一深度學習核心環節。不過與英偉達Tensor Core相比,蘋果的解決方案在浮點精度支持(如FP8、FP6)與運算效率上仍存在差距。英偉達Tensor Core不僅支持多精度計算,還能與主流AI框架無縫協作,這是當前蘋果GPU需要追趕的方向。
此前蘋果力推的神經網絡引擎(ANE)因使用門檻高與性能落后逐漸被開發者冷落。該引擎要求模型轉換為特定格式,且內存帶寬僅約120GB/s,遠不及2016年消費級顯卡水平。意識到大模型對內存容量的需求,蘋果在M4芯片中已嘗試配置最高512GB統一內存。若未來M5 Max采用LPDDR6內存,帶寬有望提升至900GB/s,將具備與主流顯卡競爭的實力。